

2023/11/14
2 min
MonetDB Solutions is pleased to introduce Long Term Support (LTS) versions of MonetDB. This marks a significant step in our commitment to provide a stable and reliable database management system for our users.
Read the Article
2022/07/21
2 min
Amsterdam 21/7/2022. MonetDB Solutions announced today that Niels Nes has been appointed the company’s new CEO. As an experienced business leader, Nes will succeed Martin Kersten, who sadly passed away on 6 July 2022, and take the lead over the company as of now.
Read the Article
2022/07/11
3 min
Prof. Dr. M.L. (Martin) Kersten, fellow of the national research institute Centrum Wiskunde & Informatica (CWI) in Amsterdam, emeritus professor of computer science at the University of Amsterdam and CEO of MonetDB Solutions, passed away on 6 July 2022.
Read the Article
2022/04/13
4 min
A Cloud Data Warehouse Diagnosis For over a decade, Cloud-enabled database systems have emerged. The generic architecture is: The persistent store is the Cloud global file store, such as S3, GFS and Azure Files.
Read the Article
2022/02/21
1 min
Today, we announce the release of the open-source analytical database server MonetDB on the Azure marketplace. We provide a free Azure image with the latest MonetDB release. You start it with your preferred Azure instance and you’re ready to go.
Read the Article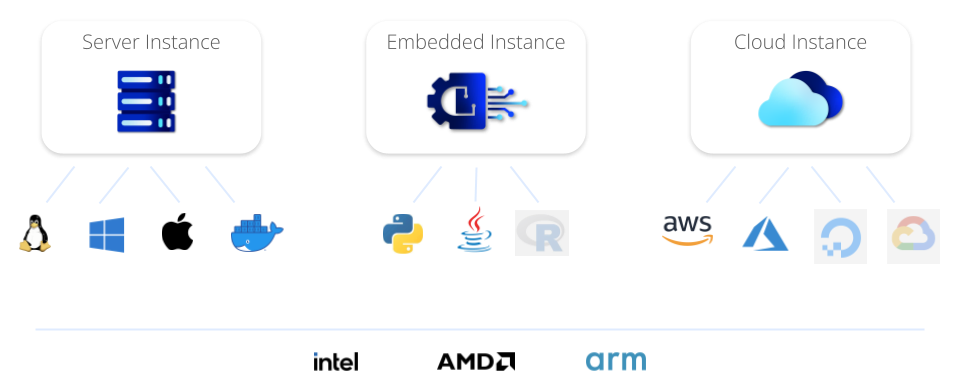
2022/01/31
4 min
Since its first open-source release in 2004, MonetDB has metamorphosed from a Linux focused research project into an end-user oriented industrial-ready product. Today, I let my most precious kākāpō fly over MonetDB’s ecosystem.
Read the Article
2021/12/20
2 min
Do you want to have a ready to use MonetDB database within minutes? Now you can. The MonetDB software is also available on the AWS marketplace. We provide a free AMI (Amazon Machine Image) with the latest MonetDB release.
Read the Article
2021/12/15
2 min
Did you know that two thirds of the land of the Netherlands was artificially won by Dutch people from the sea? For such a small country, it defies quite a number of natural concepts.
Read the Article